Analysis: 2025-26 High School Circuit
Quantifying Side Bias Through ELO Regression
The "Fair" Benchmark
In a perfectly "fair" win rate, the outcome is exactly 50% for the Affirmative and 50% for the Negative. In this scenario, the side a team is assigned is statistically irrelevant to their probability of winning. However, because human performance and judging vary, we use a "buffer zone" to define fairness in the real world.
If your bias is within ±2%, the pool is generally considered "balanced." Anything over ±5% usually suggests a specific topic or judging trend favoring one side.
Defining Bias
Bias occurs when the side assignment provides a "head start" or a "handicap" that a team must overcome. Minor Bias (±5% to ±7%) is where the community starts to notice a "lean." Teams might begin preferring one side during flip-choices, but a significantly more skilled team can still reliably overcome the disadvantage.
Significant Bias (±8% to ±12%) is where our current calculation of -10.95% falls. This is often called a "side-skewed" topic. At 10% bias, the disadvantaged side has to work significantly harder to achieve the same result as their opponent, and tournament results begin to feel like a "lottery" based on side-assignment rather than a test of skill.
Critical/Structural Bias (> ±15%) represents a "broken" topic. The win rate might look like 65% vs 35%. This usually stems from a procedural or topicality issue where one side has an argument that is nearly impossible to answer, or the resolution is worded so poorly that one side lacks a viable ground to stand on.
Including ELO
Raw win rates can be deceiving. If the 10 best teams in the country happen to be Affirmative 70% of the time, the Aff win rate will look high even if the topic is fair. By using Linear Regression, we remove the "skill noise." When we see an intercept of -10.95%, we are saying that even if we played a match between two identical robotic clones with the exact same skill level, the Affirmative clone would still lose 11% more often. That is the definition of Structural Bias.
Overall Win Rate
Prelim Rounds
Bias: -1.24%
Elimination Rounds
Bias: -4.01%
In a perfectly "fair" win rate, the outcome is exactly 50% for the Affirmative and 50% for the Negative. With 4,472 rounds processed, our data shows a deviation from this ideal. The preliminary rounds sit at a 48.76% win rate, while elimination rounds drop further to 45.99%.
If your bias is within ±2% (like our preliminary bias of -1.24%), the pool is generally considered "balanced." Anything over ±5% usually suggests a specific topic or judging trend favoring one side. Our elimination round bias of -4.01% is approaching this threshold, indicating that as the level of competition increases, the Negative advantage becomes more pronounced.
ELO Based Regression Analysis
To move beyond surface-level win rates, we must account for team skill. In our 2025-26 model, the expected probability the Affirmative (Team A) defeating the Negative (Team B) is derived from the standard ELO equation:
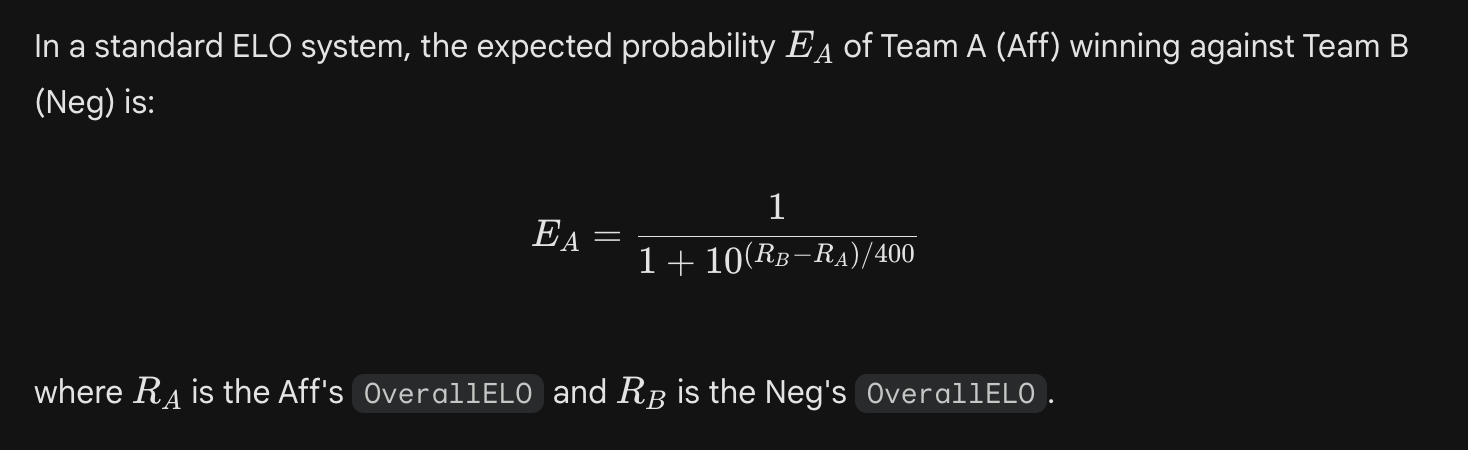
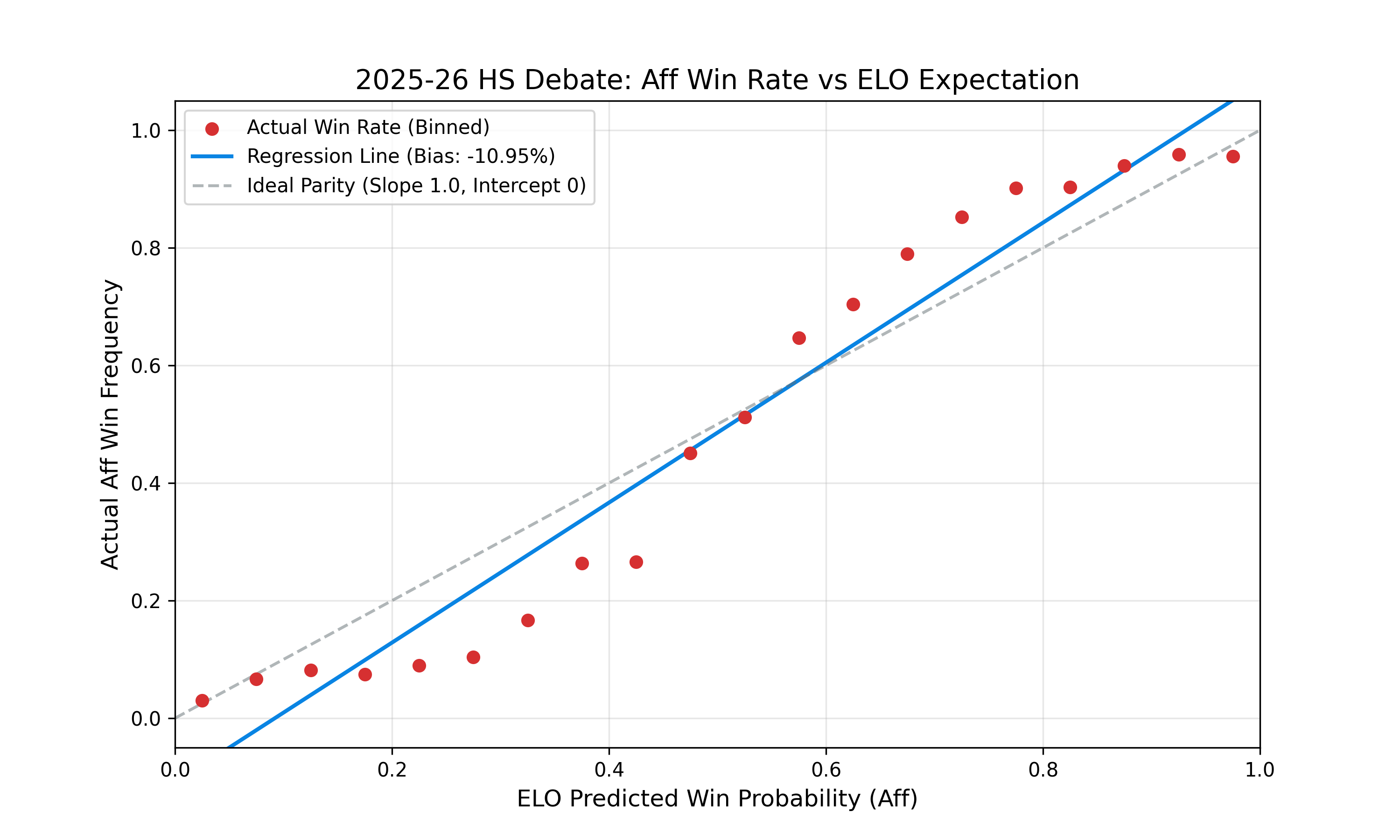
To isolate skill from side structurality, we regressed actual win outcomes against ELO-predicted win probabilities. In theory, we usually look at the deviation from a theoretical 50/50 split
The Intercept is your "True Aff Bias". If the intercept is 0.05, it means that when two perfectly matched teams (Expected Win = 0.5) debate, the Affirmative actually wins 55% of the time (0.5 + 0.05).The Slope measures how "predictive" ELO is. In a perfect world, the slope is 1.0. If it's lower (e.g., 0.7), it suggests that ELO is overestimating the impact of skill gaps, or that high-variance factors (like side bias) are flattening the skill curve.
To find the "Aff Bias" via linear regression, we aren't just looking at the raw win rate, but rather the Residuals (the difference between the actual outcome and the ELO-predicted outcome). If the Aff side consistently wins more than ELO predicts, that is a quantifiable bias.
The "Steep" Slope: A slope of 1.19 (exceeding the ideal 1.0) suggests that ELO is a potent predictor this season, but the higher-rated teams are winning even more frequently than the standard ELO curve expects.
Structural Intercept: The static bias of -10.95% is the most startling figure, representing the baseline Affirmative disadvantage when controlling for team strength.
The interaction between a slope of 1.1904 and a -10.95% intercept suggests a "compounding" effect. In a standard ELO model, we expect a slope of 1.0. Because our slope is significantly higher (1.19), it implies that skill gaps are being amplified by the current resolution or judging meta.
Essentially, higher-rated teams aren't just winning—they are winning at a rate that suggests the ELO system is actually underestimating their dominance when they are on the structurally advantaged side (the Negative).
For the Affirmative, these numbers imply a "Double-Handicap." First, they must overcome the -10.95% static bias (the Intercept), which acts as a structural penalty regardless of skill. Second, because the slope is 1.19, if an Affirmative team faces an opponent who is even slightly higher-rated, the statistical "hill" they have to climb becomes much steeper than the ELO points would normally suggest.
The R-Squared of 0.4261 is also critically important. In social sciences and competitive analytics, an R-Squared over 0.40 is considered a strong effect size. This implies that nearly 43% of the variance in win/loss outcomes is explained simply by the relationship between ELO and side assignment. In a "perfect" game of pure skill, we would want this number to be higher, but in a game with a -10.95% bias, this indicates that the side assignment is a primary driver of tournament results.
If you are a coach or competitor looking at these stats, the implication is clear: Winning on the Affirmative is currently a "high-performance" task. To maintain a 50% win rate on the Aff, a team must actually be significantly more skilled than the field to compensate for the -10.95% structural headwind.
Code
The following Python code demonstrates how we extracted the necessary attributes from our DynamoDB table.
import boto3
from decimal import Decimal
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def calculate_aff_bias():
# Initialize the DynamoDB resource
dynamodb = boto3.resource('dynamodb', region_name='us-east-1') # Change to your region
table = dynamodb.Table('Debate_Rounds_2025-26_HS')
print("Fetching data from DynamoDB...")
# Scanning the table
# Note: If you have > 1MB of data, you'd need to handle pagination
response = table.scan(
ProjectionExpression="AffirmativeWin, PreliminaryRound"
)
items = response.get('Items', [])
# Counters
stats_dict = {
"Prelim": {"wins": 0, "total": 0},
"Elim": {"wins": 0, "total": 0}
}
for item in items:
# Determine if it's a prelim or elim
is_prelim = item.get('PreliminaryRound') == 'Yes'
category = "Prelim" if is_prelim else "Elim"
# Determine if Aff won
aff_won = item.get('AffirmativeWin') == 'Yes'
stats_dict[category]["total"] += 1
if aff_won:
stats_dict[category]["wins"] += 1
# Print Results
print("\n--- Debate Statistics 2025-26 ---")
total_all = len(items)
for cat, data in stats_dict.items():
if data["total"] > 0:
win_rate = (data["wins"] / data["total"]) * 100
bias = win_rate - 50
print(f"{cat} Rounds:")
print(f" Total: {data['total']}")
print(f" Aff Win Rate: {win_rate:.2f}%")
print(f" Aff Bias: {bias:+.2f}%") # Shows + or - prefix
else:
print(f"{cat} Rounds: No data found.")
print(f"\nProcessed {total_all} total rounds.")
def calculate_elo_regression():
dynamodb = boto3.resource('dynamodb', region_name='us-east-1') # Change to your region
# 1. Fetch all Teams to get their ELOs
team_table = dynamodb.Table('Team_Info_2025-26_HS')
teams_items = team_table.scan(ProjectionExpression="SchoolTeamCode, OverallELO").get('Items', [])
elo_map = {item['SchoolTeamCode']: float(item['OverallELO']) for item in teams_items}
# 2. Fetch all Rounds
round_table = dynamodb.Table('Debate_Rounds_2025-26_HS')
rounds = round_table.scan(ProjectionExpression="AffirmativeSchool, NegativeSchool, AffirmativeWin").get('Items', [])
x_expected = [] # ELO Predicted Win Probabilities
y_actual = [] # Actual Outcomes (1 for Win, 0 for Loss)
for r in rounds:
aff_code = r.get('AffirmativeSchool')
neg_code = r.get('NegativeSchool')
if aff_code in elo_map and neg_code in elo_map:
ra = elo_map[aff_code]
rb = elo_map[neg_code]
# Standard ELO Expected Win Probability for Aff
expected_win = 1 / (1 + 10 ** ((rb - ra) / 400))
actual_win = 1 if r.get('AffirmativeWin') == 'Yes' else 0
x_expected.append(expected_win)
y_actual.append(actual_win)
x = np.array(x_expected)
y = np.array(y_actual)
# 3. Linear Regression
# We are regressing Actual Outcome vs Expected Probability
slope, intercept, r_value, p_value, std_err = stats.linregress(x_expected, y_actual)
print(f"--- ELO Regression Analysis ---")
print(f"Sample Size: {len(y_actual)} rounds")
print(f"Slope: {slope:.4f} (Ideal: 1.0)")
print(f"Intercept: {intercept:.4f} (Ideal: 0.0)")
print(f"R-Squared: {r_value**2:.4f}")
# Interpretation
aff_advantage = intercept * 100
print(f"\nStatic Aff Bias: {aff_advantage:+.2f}%")
if intercept > 0:
print("Interpretation: Even when ELO predicts a 0% win chance, Aff starts with a baseline advantage.")
# 4. Create the Plot
plt.figure(figsize=(10, 6))
# Binning data for a cleaner scatter visualization
bins = np.linspace(0, 1, 21) # 5% increments
bin_centers = (bins[:-1] + bins[1:]) / 2
bin_win_rates = []
for i in range(len(bins)-1):
mask = (x >= bins[i]) & (x < bins[i+1])
if np.any(mask):
bin_win_rates.append(np.mean(y[mask]))
else:
bin_win_rates.append(np.nan)
# Plot binned actual data
plt.scatter(bin_centers, bin_win_rates, color='#d63031', label='Actual Win Rate (Binned)', zorder=3)
# Plot the Regression Line
line_x = np.array([0, 1])
line_y = slope * line_x + intercept
plt.plot(line_x, line_y, color='#0984e3', linewidth=2, label=f'Regression Line (Bias: {intercept*100:.2f}%)')
# Plot the Ideal 50/50 Line for reference
plt.plot([0, 1], [0, 1], color='#636e72', linestyle='--', alpha=0.5, label='Ideal Parity (Slope 1.0, Intercept 0)')
# Formatting
plt.title('2025-26 HS Debate: Aff Win Rate vs ELO Expectation', fontsize=14)
plt.xlabel('ELO Predicted Win Probability (Aff)', fontsize=12)
plt.ylabel('Actual Aff Win Frequency', fontsize=12)
plt.legend()
plt.grid(alpha=0.3)
plt.ylim(-0.05, 1.05)
plt.xlim(0, 1)
# Save and Show
plt.savefig('debate_bias_regression.png', dpi=300)
plt.show()
return slope, intercept
if __name__ == "__main__":
calculate_aff_bias()
calculate_elo_regression()
This raw data was then cross-referenced with our team ELO table to calculate the residuals used in our final regression model. The model includes all TOC tounamens until February 12, 2026. Notably it does not include Berkeley, Harvard, or the GBN Spartan Green/Gold.